class: center, middle, inverse, title-slide # Comparaison de génomes microbiens ## Cycle de formation à la bioinformatique par la pratique ### Hélène Chiapello - Valentin Loux <br/>(helene.chiapello|valentin.loux)<span class="citation">@inrae.fr</span> ### 2022/05/10 --- # Practical informations - 9h30 - 17h00 - 2 breaks in the morning and in the afternoon - Lunck break of 1 hour <!-- - First session remote for this module … please be comprehensive ! --> <br/><br/> <br/><br/> <br/><br/> <br/><br/> <br/><br/> <br/><br/> <p xmlns:cc="http://creativecommons.org/ns#" xmlns:dct="http://purl.org/dc/terms/"><a property="dct:title" rel="cc:attributionURL" href="https://formations.migale.inrae.fr/Comparative_Genomics/slides.html">These supports, </a> by <a rel="cc:attributionURL dct:creator" property="cc:attributionName" href="https://migale.inrae.fr">INRAE-Migale Bioinformatics Facility</a> are licensed under <a href="http://creativecommons.org/licenses/by-sa/4.0/?ref=chooser-v1" target="_blank" rel="license noopener noreferrer" style="display:inline-block;">CC BY-SA 4.0<img style="height:22px!important;margin-left:3px;vertical-align:text-bottom;" src="https://mirrors.creativecommons.org/presskit/icons/cc.svg?ref=chooser-v1"><img style="height:22px!important;margin-left:3px;vertical-align:text-bottom;" src="https://mirrors.creativecommons.org/presskit/icons/by.svg?ref=chooser-v1"><img style="height:22px!important;margin-left:3px;vertical-align:text-bottom;" src="https://mirrors.creativecommons.org/presskit/icons/sa.svg?ref=chooser-v1"></a></p> <!-- Microbial genomes Comparison Training © 2021 by INRAE-Migale Bioinformatics Facility is licensed under CC BY-SA 4.0. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/4.0/ --> --- # A quick round table presentation <!-- Take your Post-It on [Scrumblr](http://scrumblr.ca/Formation_Migale_Module_9bis) and tell us : --> * Who are you ? - Institution, laboratory, position … * Are you (somewhat) familiar with Galaxy ? * What are your needs in microbial genomes comparison ? * Have you already dealt with microbial genomics data ? - Aim of the study ? - Species studied - Number of genomes - Difficulties ? * How do you feel today ? Ok or Ko ? --- # Migale team <img src="images/migale-orange.png" width="50%" style="display: block; margin: auto;" /> * <a href="https://migale.inrae.fr/">Migale website</a> * INRAE infrastructure dedicated to provide - Calculation & storage infrastructure - Trainings - Data analysis service (collaboration or accompaniement) - Bioinformatics tool development * Member of the Institut Français de Bioinformatique --- # Objectives After this training, you will: * Be able to construct a genomic dataset from public ressources and evaluate its quality and diversity * Know the outlines, advantages and limits of main microbial genome comparison approaches * Be able to use several tools like .large[**dRep**], .large[**MAUVE**] and .large[**ROARY**] under Galaxy or using a graphical interface on the training data set * Have some keys to interpret results --- # Program <!-- 09h00-17h --> * Morning: + Dataset construction + Dataset quality evaluation + Dataset diversity analysis + Genome alignment * Afternoon: + Pan-Genome construction + First steps in phylogenomics + Data visualization and interpretation --- class: heading-slide, middle, center # Microbial comparative genomics --- # A huge number of microbial genomes Bacterial and metagenomic genome projects: the top of the sequencing projects .pull-left[ <img src="images/gold-total-genomes.png" width="100%" style="display: block; margin: auto;" /> ] -- .pull-right[ <img src="images/gold-proka-genomes.png" width="90%" style="display: block; margin: auto;" /> ] Proteobacteria and Firmicutes: the two most sequenced group of genomes Source: <a href="https://gold.jgi.doe.gov/statistics">GOLD statistics</a> --- # And there is still a lot more to explore, especially for microbes .pull-left[ <img src="images/TreeofLife_New_BactNonCultivables.jpg" width="80%" style="display: block; margin: auto;" /> ] -- .pull-right[ - genomic data where recovered from diverse metagenomic samples - tree reconstructed from an alignemnt of 16 ribosomal proteins - red dots indicate lineages lacking an isolated representative - there are a large number of major lineages without isolated representatives ] Source : Hug, L., Baker, B., Anantharaman, K. et al. A new view of the tree of life. Nat Microbiol 1, 16048 (2016). https://doi.org/10.1038/nmicrobiol.2016.48 --- # Frequent problems for microbial genome analysis and comparison * Heterogenous quality of sequencing and assembly * Presence of huge number or public genomes OR absence of any close genomes of the same species in public databases * Difficulties regarding microbial taxonomy (classification) and nomenclature (naming of genus, species and strain naming) for many non-model organisms --- # Why comparative genomics * Answer to (not so simple) questions like : - What is the genomic diversity into a microbial species / genus ? - Is the genome structure conserved into a species / genus ? - How does the gene repertory evolves into a species / genus ? - Does this diversity could explain a given phenotype : - metabolism - probiotics (anti-inflamatory) - pathogenicity - … --- # The training dataset We will work on a reduced dataset of public *Salmonella* genomes .pull-left[ <img src="images/SalmonellaClassification.Png" width="100%" style="display: block; margin: auto;" /> ] -- .pull-right[ <img src="images/SalmonellaNCBI.png" width="100%" style="display: block; margin: auto;" /> 13.327 salmonella enterica public assemblies at NCBI! ] --- # The training dataset: a list of 16 salmonella enterica public genomes (part 1) Assembly_accession|Subspecies|Serotype|Strain|assembly_level ------------------|----------|--------|------|-------------- GCF_001951465.1|arizonae|18:z4,z23|CVM N27|Scaffold GCF_001448925.1|arizonae|62:z36|5335/86|Contig GCF_000756465.1|arizonae|62:z36|RKS2983|Complete Genome GCF_000018625.1|arizonae|62:z4|z23|Complete Genome GCF_000983595.1|enterica|ParatyphiA|na|Scaffold GCF_000026565.1|enterica|ParatyphiA|AKU_12601|Complete Genome GCF_000011885.1|enterica|ParatyphiA|ATCC 9150|Complete Genome GCF_000484015.1|enterica|ParatyphiB|SARA61|Contig --- # The training dataset: a list of 16 salmonella enterica public genomes (part 2) Assembly_accession|Subspecies|Serotype|Strain|assembly_level ------------------|----------|--------|------|-------------- GCF_001951465.1|arizonae|18:z4,z23|CVM N27|Scaffold GCF_900002585.1|enterica|Typhi|na|Scaffold GCF_000256015.1|enterica|Typhi|BL196|Contig GCF_000195995.1|enterica|Typhi|CT18|Complete Genome GCF_000007545.1|enterica|Typhi|Ty2|Complete Genome GCF_001120665.1|enterica|Typhimurium|DT104|Scaffold GCF_000006945.2|enterica|Typhimurium|LT2|Complete Genome GCF_000210855.2|enterica|Typhimurium|SL1344|Complete Genome GCF_000312745.2|enterica|Typhimurium|STm6|Contig --- class: heading-slide, middle, center # Dataset construction --- # Dataset building * Genomes of interest could be - already published and available at public databanks (ENA, NCBI, …) - **private**, not yet published. * At least, we need : - [as much as possible] complete genome assemblies (contigs / scaffolds in fasta format) - Syntactic and functional annotation : - Genbank or GFF format * For private genomes, you could/should use Prokka [*See module 9*] * It's always better if annotation is homogeneous --- class: heading-slide, middle, center # Quick reminder on format --- #FASTA format The FASTA format is used to represent sequence information. The format is very simple: - A <code>></code> symbol on the FASTA header line indicates a fasta record start. - A string of letters called the sequence id may follow the <code>></code> symbol. - The header line may contain an arbitrary amount of text (including spaces) on the same line. - Subsequent lines contain the sequence. -- <i>Example</i> ```bash >foo ATGCC >bar other optional text could go here CCGTA >bidou ACTGCAGT TTCGN >repeatmasker ATGTGTcggggggATTTT >prot2; my_favourite_prot MTSRRSVKSGPREVPRDEYEDLYYTPSSGMASP ``` --- #Genbank Format The Genbank format is used to represent sequence **and** annotation information together. - The start of the annotation section is marked by a line beginning with the word **“LOCUS”**. - Features (CDS, genes) are annotaed with thier position , strand and qualifiers that contains the n annotation. - The start of sequence section is marked by a line beginning with the word **“ORIGIN”** and the end of the section is marked by a line with only **“//”**. - NCBI, ENA (European Nucleotide Archive) et DDBJ (Japan) entries are synchronized each day. - Those three bank agree on the list of feature / qualifier that one can use to annotate sequence. --- # Genbank entry example ```bash LOCUS SCU49845 5028 bp DNA PLN 21-JUN-1999 DEFINITION Saccharomyces cerevisiae partial genes. ACCESSION U49845 VERSION U49845.1 GI:1293613 KEYWORDS . SOURCE Saccharomyces cerevisiae (baker's yeast) ORGANISM Saccharomyces cerevisiae Eukaryota; Fungi; Ascomycota; Saccharomycotina; Saccharomycetes; Saccharomycetales; Saccharomycetaceae; Saccharomyces. REFERENCE 1 (bases 1 to 5028) AUTHORS Torpey,L.E., Gibbs,P.E., Nelson,J. and Lawrence,C.W. TITLE Cloning and sequence of REV7, a gene whose function is required for DNA damage-induced mutagenesis in Saccharomyces cerevisiae JOURNAL Yeast 10 (11), 1503-1509 (1994) PUBMED 7871890 FEATURES Location/Qualifiers source 1..5028 /organism="Saccharomyces cerevisiae" /db_xref="taxon:4932" /chromosome="IX" /map="9" CDS <1..206 /codon_start=3 /product="TCP1-beta" /protein_id="AAA98665.1" /db_xref="GI:1293614" /translation="SSIYNGISTSGLDLNNGTIADMRQLGIVESYKLKRAVVSSASEA AEVLLRVDNIIRARPRTANRQHM" ORIGIN 1 gatcctccat atacaacggt atctccacct caggtttaga tctcaacaac ggaaccattg 61 ccgacatgag acagttaggt atcgtcgaga gttacaagct aaaacgagca gtagtcagct 121 ctgcatctga agccgctgaa gttctactaa gggtggataa catcatccgt gcaagaccaa // ``` --- ## GFF format The **General Feature Format** contains annotation and (optionally) sequence. It consists of one line per feature, each containing 9 columns of data, plus optional track definition line. <i><Example/i> ```bash ##gff-version 3 ##sequence-region NZ_LHTK01000001 1 688985 # organism Salmonella enterica subsp. arizonae serovar 62:z36:- str. 5335/86 # date 17-JAN-2020 NZ_LHTK01000001 GenBank contig 1 688985 . + 1 ID=NZ_LHTK01000001;Dbxref=BioProject:PRJNA224116,taxon:1245396;Name=NZ_LHTK01000001;Note=Salmonella enterica subsp. arizonae serovar 62:z36:- str. 5335/86 ssp-IIIa_O62_mirahybrid1_c1%2C whole genome shotgun sequence.,REFSEQ INFORMATION: The reference sequence was derived from LHTK01000001. The annotation was added by the NCBI Prokaryotic Genome Annotation Pipeline (PGAP). Information about PGAP can be found here: https://www.ncbi.nlm.nih.gov/genome/annotation_prok/ \n##Genome-Assembly-Data-START##\nAssembly Method :: MIRA v. 3.9.18\nGenome Representation :: Full\nExpected Final Version :: Yes\nGenome Coverage :: 80.89x\nSequencing Technology :: 454,Illumina MiSeq\n##Genome-Assembly-Data-END##;collected_by=Institut Pasteur%2C Paris%2C France;collection_date=1986;comment1=REFSEQ INFORMATION: The reference sequence was derived from LHTK01000001. The annotation was added by the NCBI Prokaryotic Genome Annotation Pipeline (PGAP). Information about PGAP can be found here: https://www.ncbi.nlm.nih.gov/genome/annotation_prok/ \n##Genome-Assembly-Data-START##\nAssembly Method :: MIRA v. 3.9.18\nGenome Representation :: Full\nExpected Final Version :: Yes\nGenome Coverage :: 80.89x\nSequencing Technology :: 454%3B Illumina MiSeq\n##Genome-Assembly-Data-END##;country=USA;date=17-JAN-2020;host=Homo sapiens;mol_type=genomic DNA;organism=Salmonella enterica subsp. arizonae serovar 62:z36:- str. 5335/86;serogroup=O62;serovar=62:z36:-;strain=5335/86;sub_species=arizonae;submitter_seqid=ssp-IIIa_O62_mirahybrid1_c1 NZ_LHTK01000001 GenBank pseudogene 1 1014 . - 1 ID=LFZ49_RS22320.pseudogene;Alias=LFZ49_RS22320;Name=LFZ49_RS22320;pseudo=_no_value NZ_LHTK01000001 GenBank gene 1011 1634 . - 1 ID=LFZ49_RS00010;Name=LFZ49_RS00010;old_locus_tag=LFZ49_00010 NZ_LHTK01000001 GenBank mRNA 1011 1634 . - 1 ID=LFZ49_RS00010.t01;Parent=LFZ49_RS00010 ``` --- # Practical : public genomes #1 How to gather a list of public genomes of interest ? - Work from the [prokaryotic public genomes available at NCBI](https://www.ncbi.nlm.nih.gov/genome/browse#!/prokaryotes/) - Use the interface to filter, then download this table - From this list of **accession** you will have to download a list of files. --- class: heading-slide, middle, center # Demonstration : download genbank and nct fasta file from NCBI --- # Practical : Public genomes - NCBI web site * Go to the NCBI web site * https://www.ncbi.nlm.nih.gov/ * browse to the "Genomes" section <div class="figure" style="text-align: center"> <img src="images/recup-genomes-1.png" alt="NCBI web site " width="50%" /> <p class="caption">NCBI web site </p> </div> --- # Practical : Public genomes list * You will obtain a list of *complete* genomes with different informations : - accession (unique id) number - species - strain - completeness - **a link to download the genome file(s)** (Refseq or Deposited) <div class="figure" style="text-align: center"> <img src="images/recup-genomes-2.png" alt="NCBI web site public genome list " width="50%" /> <p class="caption">NCBI web site public genome list </p> </div> https://www.ncbi.nlm.nih.gov/genome/browse#!/overview/ --- # Practical : Public genomes - filter and download * The list can be - filtered with the *filter* button - downloaded (csv file) with the "download" button <div class="figure" style="text-align: center"> <img src="images/recup-genomes-3.png" alt="NCBI web site public genome list- filter" width="50%" /> <p class="caption">NCBI web site public genome list- filter</p> </div> --- # Practical : Public genomes - Remote Web Site Structure Exploration * Explore the remote web site. * Example : - accession **GCA_003181115.1_ASM318111v1** - **FTP directory** : [ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/003/181/115/GCA_003181115.1_ASM318111v1](ftp://ftp.ncbi.nlm.nih.gov/genomes/all/README.txt) * Different file format, including : - *accession*_genomic_gbff.gz : compressed **Genbank file** - *accession*_genomic_fna.gz : compressed **genomic Fasta file** - Full description : [ftp://ftp.ncbi.nlm.nih.gov/genomes/all/README.txt](ftp://ftp.ncbi.nlm.nih.gov/genomes/all/README.txt) <div class="figure" style="text-align: center"> <img src="images/recup-genomes-4.png" alt="NCBI web site public genome list- filter" width="50%" /> <p class="caption">NCBI web site public genome list- filter</p> </div> --- # How to dowload a list of genomes files in Galaxy ? * **Galaxy** can handle list of files to download. * Needs only a **list of URLs** (http, ftp protocols) * But, no simple way to have a direct download link to a (Genbank|GFF|Fasta) file. - We will have to manipulate the tabular file to reconstruct the URL with a concatenation of - FTP site ( column **FTP**) - accession number (end of URL in column **FTP**) - file suffix (ex: *genomic_fna.gz*) From : [ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/003/181/115/GCA_003181115.1_ASM318111v1](ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/003/181/115/GCA_003181115.1_ASM318111v1) to ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/003/181/115/GCA_003181115.1_ASM318111v1/\\\\ GCA_003181115.1_ASM318111v1_genomic_fna.gz * **Two ways** of doing this : - In your favorite spreadsheet software (Excel, LibreOffice) - Directly in **Galaxy** with Rule-based upload. --- # Practical : Public genomes - Connect to galaxy  https://galaxy.migale.inrae.fr --- # Practical : Public genomes list - Upload - Select upper-left upload button - Upload the csv file, convert it to tabular (pen icon) - Upload button (again) - Rule-based tab - Load tabular from history - Build You will then be able to apply a list of **rules and transformation** to this tabular file. 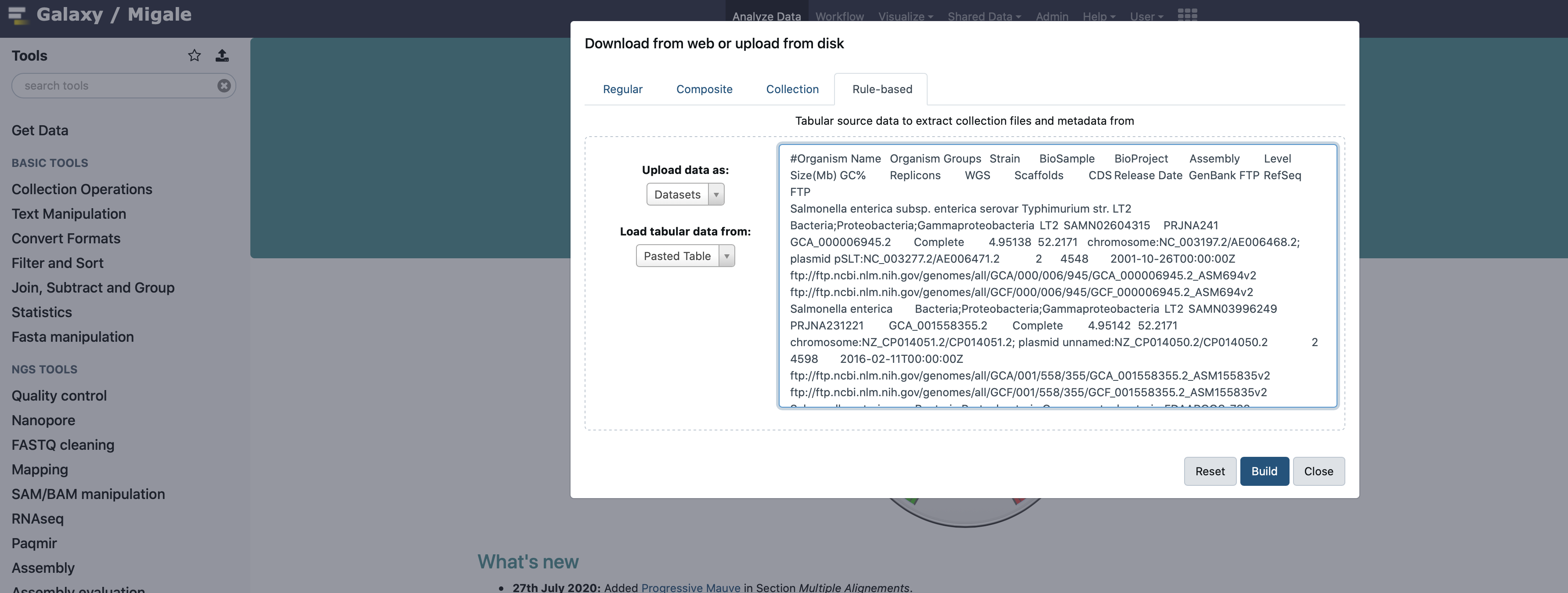 --- # Practical : Public genomes list - Remove first row <img src="images/recup-genomes-9.png" width="20%" style="display: block; margin: auto;" /> --- # Practical : Public genomes list- Extract id(1) Use a *regular expressions* to extract the id <img src="images/recup-genomes-10.png" width="20%" style="display: block; margin: auto;" /> --- # Practical : Public genomes list- Extract id(2) Use a *regular expressions* to extract the id : - Applied a column P - Create column matching expression groups (between brackets) : - ftp://.\*/(.\*) - ".*" means any character - This expression means, capture all the character you found after the last / - It will create a new column with what they have captured on each line <img src="images/recup-genomes-11.png" width="40%" style="display: block; margin: auto;" /> --- # Practical : Public genomes list - Identify Column with ID - Column Q is now filled with the ID  --- # Practical : Public genomes list - Add a column with fixed value - Add a column with "/" - Add a column with "suffix" (*ie* genomic_fna.gz) <img src="images/recup-genomes-13.png" width="30%" style="display: block; margin: auto;" /> --- # Practical : Public genomes list - Concatenate columns - Conactenate column "URL" and "fixed value with /" - Conactenate preceding column and accession - Conactenate preceding column and suffix <img src="images/recup-genomes-14.png" width="30%" style="display: block; margin: auto;" /> --- # Practical : Public genomes list - Define columns - define the last column (with the URL to the file you have constructed) as an URL - It will tell Galaxy where to look for the files to downlaod <img src="images/recup-genomes-16.png" width="30%" style="display: block; margin: auto;" /> --- # Practical : Public genomes list - Define columns(2) - [Optional] define the accession column as a "name" - It will tell Galaxy where to look for the name to give to the files downloaded (otherwise it gives the URL as the name) <img src="images/recup-genomes-15.png" width="30%" style="display: block; margin: auto;" /> --- # Practical : Public genomes list - Upload files form built list - Check the rules - Save it (wrench icon) for later - click on upload <img src="images/recup-genomes-17.png" width="30%" style="display: block; margin: auto;" /> --- # Practical : Public genomes list - Launch Upload <img src="images/recup-genomes-20.png" width="30%" style="display: block; margin: auto;" /> * The tabular genome description file is in "Shared Data/ Data Library/ Formation Génomique Comparée/DataSet/DataSalmonella.tabular" * The backup of the rules file is in "Shared Data/ Data Library/ Formation Génomique Comparée/ Correction/rule_based_ipload.json". * Rules should be adapted to your tabular file --- # Practical : create your dataset in galaxy - Connect to Galaxy(https://galaxy.migale.inrae.fr) with your (or stage) account. - Do not forget to login (upper right …) - Create a new history - Copy all the genomes fasta & GFF from "Shared Data / Data Libraries/ Formation Génomique Comparée/ Dataset/Fasta" and "Shared Data / Data Libraries/ Formation Génomique Comparée/ Dataset/GFF" --- class: heading-slide, middle, center # Quality control --- ## Why QC'ing your genomes ? **Try to answer to (not always) simple questions :** -- - What is the "quality" of an assembly [compared to what we expect] ? Is the assembly fragmented ? - Length - Number of contigs - Number of scaffolds - GC% - What is the "quality" of an annotation [compared to what we expect]? - Number of (pseudo)genes - number of rRNA genes - number of tRNA genes --- # Tools to QC your dataset : **Quast** (Quality Assessment Tool for Genome Assemblies, <a name=cite-Gurevich2013></a>([Gurevich, Saveliev, Vyahhi, and Tesler, 2013](https://doi.org/10.1093/bioinformatics/btt086)) ) is an easy to use software to evaluate genome assemblies. It gives you, in one single report different metrics about one or more assemblies. *Without* reference : - Number of contigs / scaffolds (>0, >500bp, > 1kb) - Largest contig - N50 : the sequence length of the **shortest contig** at 50% of the total genome length (equivalent to a median of contig lengths) - Number of Ns in the consensus sequence. Additional metrics ** with a reference** genome : - NG50 (N50 for reference genome size) - number of "misassemblies" --- # Practical : Quast your dataset ! ## Apply quast to the 16 assemblies of you dataset. --- class: center, middle  --- class: heading-slide, middle, center # Dataset diversity analysis --- # Genome diversity evaluation ## Why ? - Build and de-replicate genome datasets - Estimate genome similarity in a dataset and design an adapted comparative strategy -- ## How ? - Alignment based approaches (ANI) - k-mer based approaches (MASH) --- # Average Nucleotide Identity (ANI) .pull-left[ - Meet the need for a robust measure of genomic reladness and a systematic and scalable species assignation technique - Mean identity percent of aligned regions of a pair of genomes - Rely on pairwise alignments that may come either from aligned core genes or from genomic alignements - Can easily be used to build phylogenetics tree using distance methods - Is implemented in several bioinformatics tools (gANI, fastANI) ] .pull-rigth[ <div class="figure" style="text-align: center"> <img src="images/spiroplasma-pangenome.png" alt="Pangenomics, phylogenomics, and ANI of 31 Spiroplasma genomes." width="40%" /> <p class="caption">Pangenomics, phylogenomics, and ANI of 31 Spiroplasma genomes.</p> </div> ] --- # Average Nucleotide Identity (ANI) - ANI strongly correlates (R = 0.79 for logarithmic correlation) with the 16S rRNA gene sequence identity and can resolve areas where the 16S rRNA gene is inadequate (intra-species level) - The average rate of synonymous substitutions shows a tight correspondence to ANI, suggesting that ANI may also be a useful descriptor of the evolutionary distance - ANI shows a strong linear correlation to DNA–DNA reassociation values, and the 70% DNA–DNA reassociation standard corresponds to ≈93–94% ANI i.e. strains that show >94% ANI should belong to the same species -- <div class="figure" style="text-align: center"> <img src="images/ANI_F2.large.jpg" alt="Relationships between ANI, 16S rRNA, mutation rate, and DNA–DNA reassociation" width="80%" /> <p class="caption">Relationships between ANI, 16S rRNA, mutation rate, and DNA–DNA reassociation</p> </div> Source : <a name=cite-Konstantinidis2567></a>([Konstantinidis and Tiedje, 2005](https://www.pnas.org/content/102/7/2567)) --- # MASH: fast (meta)genome distance estimation using MinHash .pull-left[ ### Mash allows to compute a pairwise mutation distance without alignment using k-mer counts ### Mash provides two basic functions for sequence comparisons: - sketch: converts a sequence or collection of sequences into a MinHash sketch - dist: compares two sketches and returns an estimate of the Jaccard index (i.e. the fraction of shared k-mers), a P value, and the Mash distance, which estimates the rate of sequence mutation under a simple evolutionary model ] .pull-right[ <div class="figure" style="text-align: center"> <img src="images/MASH_13059_2016_997_Fig1_HTML.gif" alt="Overview of the MinHash bottom sketch strategy for estimating the Jaccard index. " width="50%" /> <p class="caption">Overview of the MinHash bottom sketch strategy for estimating the Jaccard index. </p> </div> ] Source : <a name=cite-Ondov></a>([Ondov, Treangen, Melsted, Mallonee, Bergman, Koren, and Phillippy, 2016](https://doi.org/10.1186/s13059-016-0997-x)) --- # MASH distances correlate well with ANI .pull-left[ - Dataset: 500 complete E. coli genomes - Gray lines: model relationship D = 1–ANI * Each plot column shows a different sketch size * Each plot row a different k-mer size k. . - Increasing the sketch size improves the accuracy of the MASH distance, especially for more divergent sequences. - Limit on how well the MASH distance can approximate ANI, especially for more divergent genomes (e.g. ANI considers only the core genome) ] .pull-rigth[ <div class="figure" style="text-align: center"> <img src="images/MASH_13059_2016_997_Fig2_HTML.gif" alt="Scatterplots illustrating the relationship between ANI and Mash distance for a collection of Escherichia genomes." width="40%" /> <p class="caption">Scatterplots illustrating the relationship between ANI and Mash distance for a collection of Escherichia genomes.</p> </div> ] Source : ([Ondov, Treangen, Melsted, et al., 2016](https://doi.org/10.1186/s13059-016-0997-x)) --- # dREP: comparison and de-replication .pull-left[ - dRep is a python program which performs rapid pairwise genome comparisons using genomic distances - it can be used for genome dereplication: identification of the 'same' genomes from a large set + determination of the highest quality genome in each replicate set dREP uses 2 main steps: 1. a first (rapid) clustering of genomes using MASH similarity (90% by default) 2. a second more sensitive step based on ANI on pairs of genomes that have at least a minimum level of "MASH" similarity ] .pull-right[ <div class="figure" style="text-align: center"> <img src="images/dRep_Figure1.png" alt="Assembly and de-replication with dRep" width="90%" /> <p class="caption">Assembly and de-replication with dRep</p> </div> ] Source : <a name=cite-Olm></a>([Olm, Brown, Brooks, and Banfield, 2017](https://doi.org/10.1038/ismej.2017.126)) --- # dREP important concepts and parameters 1. **dRep primary clustering use a greedy algorithm**, i.e. an algorithm that take shortcuts to run faster and generally produces "quasi-optimal" solutions. *Genomes that are not on the same MASH primary clustering will never be compared with ANI* 2. **Importance of genome completness:** MASH is very sensitive to genome completness. the more incomplete of genomes you allow into your genome list, the more you must decrease the primary cluster threshold. 3. **The secondary ANI threshold** (default value: 99%, limit: 99.99%) indicates how similar genomes need to be to be considered the “same”. Depending on the application,you may modify this parameter, i.e.: 95% ANI for species-level de-replication or 98% ANI to generate a set of genomes that are distinct when mapping short reads. 4. **The score used to pick representative genomes** takes into account several parameters such as Completeness, Contamination, strain heterogeneity and centrality (a measure of how similar a genome is to all other genomes in it’s cluster). --- #dRep commands and parameters 1. **dREp compare**: compare and cluster a set of genomes using one or two clustering steps. 2. **dREp dereplicate**: compare, cluster and dereplicate a set of genomes. During de-replication the first step is identifying groups of similar genomes, and the second step is picking a Representative Genome (RG) for each cluster. <<<<<<< HEAD **Parameters of primary and secondary clustering may have to be adjusted depending on the diversity of the dataset and on the objective of the comparison/dereplication** **Default values of dRep clustering parameters:** -pa P_ANI, --P_ani P_ANI ANI threshold to form primary (MASH) clusters (default: 0.9) -sa S_ANI, --S_ani S_ANI ANI threshold to form secondary clusters (default: 0.99) --- # dREP produce many results files .pull-left[ ### dRep rely on several other programs: 1. **Mash**: to build the primary clusters 2. **Mummer**: to perform the ANI computation on pairwise genome alignements (used by default but **fastANI** or **gANI** may also be used) 3. **checkM** (Parks et al. 2015) to determine contamination and completeness of genomes 4. **Prodigal** (Hyatte et al. 2010): to predict genes (used by checkM and gANI) 4. **cipy** (Jones et al. 2001) to produce a final hierarchical clustering. ] .pull-right[ ### Output files of dRep <div class="figure" style="text-align: center"> <img src="images/dRep_output_files.png" alt="dRep results" width="90%" /> <p class="caption">dRep results</p> </div> ] Source : ([Olm, Brown, Brooks, et al., 2017](https://doi.org/10.1038/ismej.2017.126)) --- # Practice - use **dREP-dreplicate** to explore the Salmonella genome dataset diversity and completenes and dereplicate the dataset - explore and interpret results - input : 16 genome fasta files <div class="figure" style="text-align: center"> <img src="images/dRep_galaxy.png" alt="dRep on mMigale Galaxy server" width="60%" /> <p class="caption">dRep on mMigale Galaxy server</p> </div> --- # dRep results interpretation Important outputs of dRep .pull-left[ The "Secondary_clustering_dendrograms.pdf" output file <div class="figure" style="text-align: center"> <img src="images/dRep_Secondary_clustering_dendrograms.png" alt="Secondary_clustering_dendrograms.pdf" width="70%" /> <p class="caption">Secondary_clustering_dendrograms.pdf</p> </div> ] -- .pull-right[ the "Winning_genomes.pdf" output file and the deReplicated genomes list <div class="figure" style="text-align: center"> <img src="images/dRep_Scoring_Winning_genomes.png" alt="Winning_genomes.pdf" width="70%" /> <p class="caption">Winning_genomes.pdf</p> </div> ] --- class: heading-slide, middle, center # Genome alignment --- #Genome alignment .pull-left[ - Mostly targeted to **close genome comparisons** (generally at the intra-species level) - A variety of applications: - help for genome assembly, scaffolding and annotation - genome architecture comparison - genome micro-evolution analysis - discovery of DNA motifs or elements in conserved non-coding regions - .... - Aligning whole genome sequences is a challenge: - computational intensive - heterogenous quality of assemblies - broad variety of mutational and evolutionary events (including rearrangemnets) - result analysis, interpretion and visualisation is tricky ] .pull-rigth[ <div class="figure" style="text-align: center"> <img src="images/Alignement_geneomes_12859_2006_Article_1172_Fig1_HTML.jpg" alt="An approximate phylogeny of genome comparison tools over the past 30 years" width="30%" /> <p class="caption">An approximate phylogeny of genome comparison tools over the past 30 years</p> </div> Source : <a name=cite-Treangen></a>([Treangen and Messeguer, 2006](https://doi.org/10.1186/1471-2105-7-433)) ] --- #Mummer: pairwise alignment with rearrangments Based on three main steps: #### Step 1: Perform a maximal unique match (MUM) decomposition of the two genomes using suffix trees <div class="figure" style="text-align: center"> <img src="images/Mummer1.png" alt="A maximal unique matching subsequence (MUM) of 39 nt (shown in uppercase) shared by Genome A and Genome B" width="40%" /> <p class="caption">A maximal unique matching subsequence (MUM) of 39 nt (shown in uppercase) shared by Genome A and Genome B</p> </div> -- <div class="figure" style="text-align: center"> <img src="images/Mummer2.png" alt="A Suffix tree for the sequence gaaccgacct" width="40%" /> <p class="caption">A Suffix tree for the sequence gaaccgacct</p> </div> Source : <a name=cite-Delcher1999></a>([Delcher, Kasif, Fleischmann, Peterson, White, and Salzberg, 1999](https://doi.org/10.1093/nar/27.11.2369)) --- #Mummer: pairwise alignment with rearrangments #### Step 2: Sort the matches found in the MUM alignment, and extract the longest possible set of matches that occur in the same order in both genomes <div class="figure" style="text-align: center"> <img src="images/Mummer3.png" alt="LIS algorithm to find the longest set of MUMs whose sequences occur in ascending order in both Genome A and Genome B" width="50%" /> <p class="caption">LIS algorithm to find the longest set of MUMs whose sequences occur in ascending order in both Genome A and Genome B</p> </div> -- #### Step 3: Close the gaps (regions between the MUMs) by - detecting SNPs between MUMs - identifying large inserts (transpositions or insertions) and repeats (overlapping MUMs) - aligning small polymorphic regions using a standart dynamic programming algorithm approach Source : ([Delcher, Kasif, Fleischmann, et al., 1999](https://doi.org/10.1093/nar/27.11.2369)) --- #Mummer: pairwise alignment with rearrangments .pull-left[ #### Example of Nucmer results - Alignment of M.genitalium (580 074 nt) x M.pneumoniae (816 394 nt) - The MUM alignment clearly shows five translocations of M.genitalium sequence with respect to M.pneumoniae, in agree- ment with the analysis of Himmelreich et al. 1997 x Source : ([Delcher, Kasif, Fleischmann, et al., 1999](https://doi.org/10.1093/nar/27.11.2369)) ] .pull-rigth[ <div class="figure" style="text-align: center"> <img src="images/Mummer5.png" alt="Alignment of M.genitalium and M.pneumoniae using FASTA (top), 25mers (middle) and MUMs (bottom)" width="40%" /> <p class="caption">Alignment of M.genitalium and M.pneumoniae using FASTA (top), 25mers (middle) and MUMs (bottom)</p> </div> ] --- # Practice - Use **Galaxy-Nucmer** to align the two Salmonella typhi CT18 (Refseq accession:GCF_000195995.1) and Ty2 (Refseq accession:GCF_000007545.1) complete genomes - Look at result files - What do you conclude accorging their genome structure? - Generate a list of coordinates of aligned regions using the **Show-Coords** program -- <div class="figure" style="text-align: center"> <img src="images/Nucmer_Galaxy.png" alt="Nucmer on Galaxy" width="70%" /> <p class="caption">Nucmer on Galaxy</p> </div> --- # Nucmer result interpretation The Galaxy-nucmer outputs - The *dotplot* ouput -- <div class="figure" style="text-align: center"> <img src="images/Nucmer_dotplot.png" alt="Dotplot Salmonella SPA CT18 vs STY2" width="70%" /> <p class="caption">Dotplot Salmonella SPA CT18 vs STY2</p> </div> --- # Nucmer result interpretation The Galaxy-nucmer outputs - The *alignment* ouput <div class="figure" style="text-align: center"> <img src="images/Nucmer_tabular_format.png" alt="Dotplot Salmonella SPA CT18 vs STY2" width="90%" /> <p class="caption">Dotplot Salmonella SPA CT18 vs STY2</p> </div> --- # Nucmer result interpretation The Galaxy-nucmer outputs - The *show-coords* ouput <div class="figure" style="text-align: center"> <img src="images/show-coords.png" alt="Show-coords Salmonella SPA CT18 vs STY2" width="90%" /> <p class="caption">Show-coords Salmonella SPA CT18 vs STY2</p> </div> --- #Mauve: multiple alignment with rearrangments http://darlinglab.org/mauve/mauve.html - One of the first multiple genome aligner that can deal with rearrangments - Well suited to bacterial genome alignment - Success largely due to its Graphical User Interface Source : <a name=cite-Darling></a>([Darling, Mau, Blattner, and Perna, 2004](https://doi.org/10.1101/gr.2289704)) --- #Mauve: how it works? .pull-left[ Mauve alignment algorithm main steps: - Find local alignments (multi-MUMs). - Use the multi-MUMs to calculate a phylogenetic guide tree. - Select a subset of the multi-MUMs to use as anchors—these anchors are partitioned into collinear groups called LCBs. - Perform recursive anchoring to identify additional alignment anchors within and outside each LCB. - Perform a progressive alignment of each LCB using the guide tree. Source : ([Darling, Mau, Blattner, et al., 2004](https://doi.org/10.1101/gr.2289704)) ] .pull-rigth[ <div class="figure" style="text-align: center"> <img src="images/Mauve_78942-21f1_4o.jpg" alt="A pictorial representation of greedy breakpoint elimination in three genomes" width="30%" /> <p class="caption">A pictorial representation of greedy breakpoint elimination in three genomes</p> </div> ] --- #Mauve: Alignment of Nine Enterobacterial Genomes .pull-left[ Genome alignment features - Each contiguously colored region is a locally collinear block (LCB) - LCB can be in reverse complement orientation relatively to reference genome (K12) - 45 LCB with minimum weight of 69 consisting of 2.86 Mb of conserved backbone sequence broken into 1252 segments - Several known inversions are confirmed such as the O157:H7 EDL933 inversion relative to K12 and the large inversion about the origin of replication among the S. enterica serovars Typhi CT18 and Ty2 Source : ([Darling, Mau, Blattner, et al., 2004](https://doi.org/10.1101/gr.2289704)) ] .pull-rigth[ <div class="figure" style="text-align: center"> <img src="images/Mauve_78942-21f6_4o.jpg" alt="Locally collinear blocks identified among the nine enterobacterial genomes" width="50%" /> <p class="caption">Locally collinear blocks identified among the nine enterobacterial genomes</p> </div> ] --- #Mauve companion tools ## Mauve Contig Mover (Rissman et al. 2009) - Can order contigs of a draft genome relative to a related reference genome - Based on iterative genome alignment using Mauve and requires anchors at both ends of contigs - The reference used may be draft quality itself, or may have divergent genetic content -- ## ProgressiveMauve (Darling & Perna 2010) - Can align regions conserved only in subsets of the genomes - Set up an anchor scoring function that penalizes alignment anchoring in repetitive regions of the genome and penalizes genomic rearrangement - Use a probabilistic scoring strategy (HMM) to reject erroneous alignments of unrelated sequence produced by Mauve - In summary: can align faster and more accuratly than Mauve more distant and big dataset of genomes --- # Practice Mauve - Use *Mauve* **on your local computer** to align the 3 complete genomes of serotypes typhi (CT18, Refseq accession:GCF_000195995.1), typhimurium (LT2, Refseq accession:GCF_000006945.2) and Paratyphi A (ATCC 9150, Refseq accession: GCF_000011885.1) - Mauve input: fasta (or Genbank) files - Choose *Mauve* and **not** *ProgressiveMauve* algorithm -- <div class="figure" style="text-align: center"> <img src="images/Mauve.png" alt="Mauve on my local computer" width="70%" /> <p class="caption">Mauve on my local computer</p> </div> --- # Mauve results interpretation - Genome alignment of serotypes typhi (CT18), typhimurium (LT2) and Paratyphi A - Look at the LCB output (other output files description : http://darlinglab.org/mauve/user-guide/files.html ) - What do you conclude regarding genome structure ? -- <div class="figure" style="text-align: center"> <img src="images/MauveLT2_CT18_1TCC9150_LCB.png" alt="Mauve on ly local computer" width="70%" /> <p class="caption">Mauve on ly local computer</p> </div> --- class: heading-slide, middle, center # L U N C H --- class: heading-slide, middle, center # The microbial pan-genome --- #The microbial pan-genome .pull-left[ First term apparition in 2005 in two publications * Tettelin et al. Genome analysis of multiple pathogenic isolates of Streptococcus agalactiae: Implications for the microbial “pan-genome” Proc Natl Acad Sci U S A. * Medini et al. "The microbial pangenome" Curr Opin Genet Dev. *A bacterial species can be described by its **pan-genome** composed of a **core genome** containing genes present in all strains, and a **dispensable genome** containing genes present in two or more strains and genes unique to single strains.* ] .pull-right[ <div class="figure" style="text-align: center"> <img src="images/PanGenome.jpg" alt="Streptococcus group B pan genome" width="85%" /> <p class="caption">Streptococcus group B pan genome</p> </div> ] References: <a name=cite-Tettelin2005></a>([Tettelin, Masignani, and Cieslewicz MJ, 2005](https://doi.org/10.1073/pnas.0506758102)) and <a name=cite-Medini2005></a>([Medini, Donati, Tettelin, Masignani, and Rappuoli, 2005](http://www.sciencedirect.com/science/article/pii/S0959437X05001759)) --- #The microbial pan-genome - Definition refinment by Koonin (2008) and Collins (2012): the 3 classes of prokaryotic genes * **core (or persitent) genes**: a small fraction of highly conserved genes * **shell genes**: a larger set of moderately conserved genes * **cloud genes**: (nearly) unique genes .pull-left[ <div class="figure" style="text-align: center"> <img src="images/CoreGenome.jpg" alt="Streptococcus group B core genome" width="60%" /> <p class="caption">Streptococcus group B core genome</p> </div> ] .pull-right[ <div class="figure" style="text-align: center"> <img src="images/Koonin_panGenes_classes.jpg" alt="A Common and rare genes in selected archaeal and bacterial genomes. Red, core; green, shell; light gray, cloud; dark gray, ORFans." width="40%" /> <p class="caption">A Common and rare genes in selected archaeal and bacterial genomes. Red, core; green, shell; light gray, cloud; dark gray, ORFans.</p> </div> ] Source : <a name=cite-Koonin2008></a>([Koonin and Wolf, 2008](https://doi.org/10.1093/nar/gkn668)) Source : <a name=cite-Collins2012></a>([Collins and Higgs, 2012](https://doi.org/10.1093/molbev/mss163)) --- #Open or closed pan-genome - Some bacterial species are considered to have an unlimited large gene repertoire => **open pan-genome** - Other species seem to be limited by a maximum number of genes in their gene pool=> **closed pan-genome** - Authors use **Power or Heaps law** to fit of the overall number of genes (pan-genome) obtained according to the number of sequenced genomes .pull-left[ <div class="figure" style="text-align: center"> <img src="images/open_closed_pangenome.png" alt="Open and closed pangenomes" width="60%" /> <p class="caption">Open and closed pangenomes</p> </div> ] .pull-right[ <div class="figure" style="text-align: center"> <img src="images/OpenAndClosePanGenomes.jpg" alt="Power law regression for species with open and closed pan-genomes.Red curves indicate closed pan-genomes, green curves indicate open ones." width="60%" /> <p class="caption">Power law regression for species with open and closed pan-genomes.Red curves indicate closed pan-genomes, green curves indicate open ones.</p> </div> ] Source : <a name=cite-Tettelin2008></a>([Tettelin, Riley, Cattuto, and Medini, 2008](http://www.sciencedirect.com/science/article/pii/S1369527408001239)) --- # Roary: rapid large-scale prokaryote pan genome analysis Roary, the pan genome pipeline, takes *closely related* annotated genomes in GFF3 file format and calculates the pan genome. .pull-left[ ## Input : * annotated genomes in **GFF3** format - Roary is *very* sensitive to the validity of the GFF format - GFFs generated by **Prokka** are valid - Locus tags must be uniques across datasets. - GFF from NCBI are **invalid** (sequence is missing) - Must be converted from Genbank using "Genbank to GFF3" converter ] -- .pull-right[ # What does Roary do ? - converts annotated coding sequences (CDS) into protein sequences - cluster these protein sequences iteratively by several methods ( cd-hit, all vs all blastp) - further refines clusters into orthologous genes - for each sample, determines if a gene is present/absent - uses this information to build a tree, using FastTree - overall, calculates the number of genes that are shared, and unique - optionally does an alignment of the core genes for downstream analyses ] --- # Roary workflow <img src="images/roary_wkfw.png" width="60%" style="display: block; margin: auto;" /> --- # Practical : Roary your dataset ! ## Apply roary to the 16 assemblies of you dataset. .pull-left[ * Input : - the 16 gff files * Paramaters : - All the output files selected - No specific parameter ( -split-paralog to "yes") ] .pull-right[ <img src="images/roary-galaxy.png" width="60%" style="display: block; margin: auto;" /> ] --- ## Roary outputs .pull-left[ * *Summary statistics* about number of gene in the core/pan/accessory genomes * *Gene Presence Absence* : lists each cluster of gene, the most common annotation within the cluster and which genomes it is present in. * *Core gene alignement* : a multiple alignement file of the core genes created using PRANK * *Clustered Proteins* : a file that gives for each cluster id the list of locus tags it is made of * *pan-genome reference* : this fasta file contains a single nucleotide sequence (representative) from each of the clusters in the pan genome * Other various files in R of CSF formats. ] .pull-right[ <img src="images/roary-output.png" width="80%" style="display: block; margin: auto;" /> ] --- class: center, middle  --- class: heading-slide, middle, center # Phylogenomics basics --- #A few concepts on phylogenomics - Phylogenomics definition <div class="figure" style="text-align: center"> <img src="images/Phylogenomics_definition.png" alt="Wikipedia phylogenomics definition" width="60%" /> <p class="caption">Wikipedia phylogenomics definition</p> </div> --- #A few concepts on phylogenomics - Original definition + The application of phylogenetic methods for gene function analysis (Eisen, 1996) + Organism evolution based on whole genome analyses - Recent usage: Various types of studies mixing genomics and phylogenetics, such as: + Global patterns of synteny (conserved gene order) across species + Global patterns of gene presence and absence studies across species + Genome rearrangments analyses + DNA substitution patterns seen in noncoding regions analyses + Genomic epidemiological studies + ... - These analyses can be used to understand metabolism, pathogenicity, physiology, and behavior, speciation... Reference: <a name=cite-Eisen2003></a>([Eisen and Fraser, 2003](https://science.sciencemag.org/content/300/5626/1706)) --- #Some basics about phylogenetic tree reconstruction methods 3 main methods: - Neighbor-Joining (distance matrix) - Parsimony (presence/absence patterns) - Maximum likehood method (alignment) <div class="figure" style="text-align: center"> <img src="images/Phylogenetics_methods.jpg" alt="Phylogenetics main methods" width="60%" /> <p class="caption">Phylogenetics main methods</p> </div> Reference: <a name=cite-Sleator2015></a>([Sleator, 2015](https://doi.org/10.1007/978-1-4899-7478-5_708)) --- --- # The tree Newick format *Newick* is a text-based format for representing trees in computer-readable form using (nested) parentheses and commas .pull-left[ - The tree ends with a semicolon - Interior nodes are represented by a pair of matched parentheses, separated by commas - Branch lengths are incorporated by putting a real number after a node and preceded by a colon ] .pull-right[ <div class="figure" style="text-align: center"> <img src="images/NewickFormat.png" alt="Phylogenetics main methods" width="90%" /> <p class="caption">Phylogenetics main methods</p> </div> ] Reference: <a name=cite-Stephens2016></a>([Stephens, Bhattacharya, Ragan, and Chan, 2016](https://doi.org/10.7717/peerj.2038)) --- #FastTree: Approximately Maximum-Likelihood Trees for Large Alignments FastTree 2 allows the inference of maximum-likelihood phylogenies for huge alignments - Can deal with core-gene or core-genome alignments - Can deal with hundred of thousands of sequences - Relies on robust Maximum-Likehood statistical models - Compute local support values with the Shimodaira-Hasegawa test to estimate the reliability of each split in the tree FastTree in practice: - takes as input an alignment file (Fasta or Phylip interleaved format) - needs an evolution model: JTT or WAG or LG for protein, JC or GTR for nucleotide - produces a tree in Newick format with SH support values [0-1] given as names for the internal nodes http://www.microbesonline.org/fasttree/ --- #FastTree: practice .pull-left[ Use **Galaxy-FastTree** to build a Maximum likehood tree on the aligned core-genes - input: the *Roary core genome alignment* file in fasta format - Choose *Nucleotide algnment* - Choose *GTR+CAT nucleotide evolution model* ] .pull-left[ <div class="figure" style="text-align: center"> <img src="images/Galaxy-FastTree.png" alt="Falaxy-Fasttree" width="1000%" /> <p class="caption">Falaxy-Fasttree</p> </div> ] --- class: center, middle # How can I add metadata to my tree and view results ? # The Phandango viewer --- # Phandango: an interactive viewer for bacterial population genomics - run directly in a web browser (drag files to upload data) - many possible inputs like: a phylogenetic tree (Newick format), pan-genome data (from Roary for instance), genome annotations (GFF3 format) or any metadata (in simple (CSV format) - a valuable ressource for results interpretation <div class="figure" style="text-align: center"> <img src="images/Phandango.png" alt="Phandango" width="60%" /> <p class="caption">Phandango</p> </div> https://jameshadfield.github.io/phandango/#/ Reference:<a name=cite-Hadfield2017></a>([Hadfield, Croucher, Goater, Abudahab, Aanensen, and Harris, 2017](https://doi.org/10.1093/bioinformatics/btx610)) --- # Phandango: practice Open https://jameshadfield.github.io/phandango/#/ in a web browse of your local computer .pull-left[ Upload 3 datafiles just by draging them: - the Roary gene presence-absence file - the Roary phylogenetic tree (change the extentiion file in *.tree*) - A metadata csv file: DatasetSalmonella_metadata.csv Interpret results ] -- .pull-right[ <div class="figure" style="text-align: center"> <img src="images/Phandango_salmonella_2.png" alt="Phandango results on the Salmonella dataset" width="80%" /> <p class="caption">Phandango results on the Salmonella dataset</p> </div> ] --- #FastTree results interpretation using Phandango .pull-left[ Upload the following files - the FastTree phylogenetic tree (change the extension file in *.tree*) - the metadata csv file: DatasetSalmonella_metadata.csv Interpret results ] -- .pull-right[ <div class="figure" style="text-align: center"> <img src="images/Phadango_FastTree.png" alt="FastTree result" width="100%" /> <p class="caption">FastTree result</p> </div> ] --- #Take home message - Genome comparison is still an ongoing active bioinformatics research field - Dataset construction, quality and diversity evaluation is a **mandatory** first-step and may be time-consuming - Dataset de-replication may be helpful for some well-studied organisms - Comparative strategy depends on the addressed question and on the genome diversity level - Phylogenomics approaches are powerful and promising --- class: center, middle #T H A N K #Y O U --- # References <a name=bib-Collins2012></a>[Collins, R. E. and P. G. Higgs](#cite-Collins2012) (2012). "Testing the Infinitely Many Genes Model for the Evolution of the Bacterial Core Genome and Pangenome". In: _Molecular Biology and Evolution_ 29.11, pp. 3413-3425. ISSN: 0737-4038. DOI: [10.1093/molbev/mss163](https://doi.org/10.1093%2Fmolbev%2Fmss163). eprint: https://academic.oup.com/mbe/article-pdf/29/11/3413/13648372/mss163.pdf. URL: [https://doi.org/10.1093/molbev/mss163](https://doi.org/10.1093/molbev/mss163). <a name=bib-Darling></a>[Darling, A., B. Mau, F. Blattner, et al.](#cite-Darling) (2004). "Mauve: multiple alignment of conserved genomic sequence with rearrangements". In: _Genome Research_ 14(7), pp. 1394-1403. DOI: [10.1101/gr.2289704](https://doi.org/10.1101%2Fgr.2289704). <a name=bib-Delcher1999></a>[Delcher, A., S. Kasif, R. Fleischmann, et al.](#cite-Delcher1999) (1999). "Alignment of whole genomes". In: _Nucleic Acids Res_ 27(11):, pp. 2369-2376. DOI: [10.1093/nar/27.11.2369](https://doi.org/10.1093%2Fnar%2F27.11.2369). <a name=bib-Eisen2003></a>[Eisen, J. A. and C. M. Fraser](#cite-Eisen2003) (2003). "Phylogenomics: Intersection of Evolution and Genomics". In: _Science_ 300.5626, pp. 1706-1707. ISSN: 0036-8075. DOI: [10.1126/science.1086292](https://doi.org/10.1126%2Fscience.1086292). eprint: https://science.sciencemag.org/content/300/5626/1706.full.pdf. URL: [https://science.sciencemag.org/content/300/5626/1706](https://science.sciencemag.org/content/300/5626/1706). <a name=bib-Gurevich2013></a>[Gurevich, A., V. Saveliev, N. Vyahhi, et al.](#cite-Gurevich2013) (2013). "QUAST: quality assessment tool for genome assemblies". In: _Bioinformatics_ 29.8, pp. 1072-1075. ISSN: 1367-4803. DOI: [10.1093/bioinformatics/btt086](https://doi.org/10.1093%2Fbioinformatics%2Fbtt086). eprint: https://academic.oup.com/bioinformatics/article-pdf/29/8/1072/17106244/btt086.pdf. URL: [https://doi.org/10.1093/bioinformatics/btt086](https://doi.org/10.1093/bioinformatics/btt086). --- # References(2) <a name=bib-Gurevich2013></a>[Gurevich, A., V. Saveliev, N. Vyahhi, et al.](#cite-Gurevich2013) (2013). "QUAST: quality assessment tool for genome assemblies". In: _Bioinformatics_ 29.8, pp. 1072-1075. ISSN: 1367-4803. DOI: [10.1093/bioinformatics/btt086](https://doi.org/10.1093%2Fbioinformatics%2Fbtt086). eprint: https://academic.oup.com/bioinformatics/article-pdf/29/8/1072/17106244/btt086.pdf. URL: [https://doi.org/10.1093/bioinformatics/btt086](https://doi.org/10.1093/bioinformatics/btt086). <a name=bib-Hadfield2017></a>[Hadfield, J., N. J. Croucher, R. J. Goater, et al.](#cite-Hadfield2017) (2017). "Phandango: an interactive viewer for bacterial population genomics". In: _Bioinformatics_ 34.2, pp. 292-293. ISSN: 1367-4803. DOI: [10.1093/bioinformatics/btx610](https://doi.org/10.1093%2Fbioinformatics%2Fbtx610). URL: [https://doi.org/10.1093/bioinformatics/btx610](https://doi.org/10.1093/bioinformatics/btx610). <a name=bib-Konstantinidis2567></a>[Konstantinidis, K. T. and J. M. Tiedje](#cite-Konstantinidis2567) (2005). "Genomic insights that advance the species definition for prokaryotes". In: _Proceedings of the National Academy of Sciences_ 102.7, pp. 2567-2572. ISSN: 0027-8424. DOI: [10.1073/pnas.0409727102](https://doi.org/10.1073%2Fpnas.0409727102). eprint: https://www.pnas.org/content/102/7/2567.full.pdf. URL: [https://www.pnas.org/content/102/7/2567](https://www.pnas.org/content/102/7/2567). <a name=bib-Koonin2008></a>[Koonin, E. and Y. Wolf](#cite-Koonin2008) (2008). "Genomics of bacteria and archaea: the emerging dynamic view of the prokaryotic world". In: _Nucleic Acids Res_ 36(21), pp. 6688-6719. DOI: [10.1093/nar/gkn668](https://doi.org/10.1093%2Fnar%2Fgkn668). <a name=bib-Medini2005></a>[Medini, D., C. Donati, H. Tettelin, et al.](#cite-Medini2005) (2005). "The microbial pan-genome". In: _Current Opinion in Genetics & Development_ 15.6. Genomes and evolution, pp. 589 - 594. DOI: [https://doi.org/10.1016/j.gde.2005.09.006](https://doi.org/https%3A%2F%2Fdoi.org%2F10.1016%2Fj.gde.2005.09.006). URL: [http://www.sciencedirect.com/science/article/pii/S0959437X05001759](http://www.sciencedirect.com/science/article/pii/S0959437X05001759). --- # References(3) <a name=bib-Olm></a>[Olm, M. R., C. T. Brown, B. Brooks, et al.](#cite-Olm) (2017). "dRep: a tool for fast and accurate genomic comparisons that enables improved genome recovery from metagenomes through de-replication". In: _The ISME Journal_ 11.12, pp. 2864-2868. DOI: [10.1038/ismej.2017.126](https://doi.org/10.1038%2Fismej.2017.126). URL: [https://doi.org/10.1038/ismej.2017.126](https://doi.org/10.1038/ismej.2017.126). <a name=bib-Ondov></a>[Ondov, B. D., T. J. Treangen, P. Melsted, et al.](#cite-Ondov) (2016). "Mash: fast genome and metagenome distance estimation using MinHash". In: _Genome Biology_ 17.1, p. 132. DOI: [10.1186/s13059-016-0997-x](https://doi.org/10.1186%2Fs13059-016-0997-x). URL: [https://doi.org/10.1186/s13059-016-0997-x](https://doi.org/10.1186/s13059-016-0997-x). <a name=bib-Sleator2015></a>[Sleator, R.](#cite-Sleator2015) (2015). "Phylogenetics, Overview". In: _Encyclopedia of Metagenomics: Genes, Genomes and Metagenomes: Basics, Methods, Databases and Tools_. Ed. by K. E. Nelson. Boston, MA: Springer US, pp. 577-582. ISBN: 978-1-4899-7478-5. DOI: [10.1007/978-1-4899-7478-5_708](https://doi.org/10.1007%2F978-1-4899-7478-5_708). URL: [https://doi.org/10.1007/978-1-4899-7478-5_708](https://doi.org/10.1007/978-1-4899-7478-5_708). <a name=bib-Stephens2016></a>[Stephens, T. G., D. Bhattacharya, M. A. Ragan, et al.](#cite-Stephens2016) (2016). "PhySortR: a fast, flexible tool for sorting phylogenetic trees in R". In: _PeerJ_ 4, p. e2038. ISSN: 2167-8359. DOI: [10.7717/peerj.2038](https://doi.org/10.7717%2Fpeerj.2038). URL: [https://doi.org/10.7717/peerj.2038](https://doi.org/10.7717/peerj.2038). <a name=bib-Tettelin2005></a>[Tettelin, H., V. Masignani, and e. a. Cieslewicz MJ](#cite-Tettelin2005) (2005). In: _Proc Natl Acad Sci U S A_ 102(39), pp. 13950-13955. DOI: [10.1073/pnas.0506758102](https://doi.org/10.1073%2Fpnas.0506758102).